OGPO: Sample-Efficient Full-Finetuning of Generative Control Policies
aCarnegie Mellon University · bUC Berkeley · cUniversity of Washington · dToyota Research Institute
aCarnegie Mellon University · bUC Berkeley · cUniversity of Washington · dToyota Research Institute
Generative control policies (GCPs) — diffusion- and flow-based control policies — have emerged as effective parameterizations for robot learning. This work introduces Off-Policy Generative Policy Optimization (OGPO), a sample-efficient algorithm for finetuning GCPs that maintains off-policy critic networks to maximize data reuse and propagates policy gradients through the full generative process via a modified PPO objective, using the critics as the terminal reward.
OGPO achieves state-of-the-art performance on manipulation tasks spanning multi-task settings, high-precision insertion, and dexterous control. To our knowledge, it is also the only method that can finetune poorly-initialized behavior-cloning policies to near-full task success with no expert data in the online replay buffer, and does so with little task-specific hyperparameter tuning. Through extensive empirical study, we show that OGPO substantially outperforms alternatives based on policy steering and residual corrections, and we identify the mechanisms behind its performance.
A behavior-cloning policy rarely succeeds zero-shot across the range of conditions met at deployment, and the natural remedy, improving it autonomously with reinforcement learning, is bound by the cost of real interaction. Existing methods for finetuning generative control policies sit at two ends of a tradeoff between data efficiency and the extent of policy improvement they permit.
On one end, on-policy policy-gradient methods such as DPPO finetune the entire generative process and improve aggressively, but updates require fresh rollouts, and the effective horizon grows from the task horizon $T$ to $K \times T$ over the $K$ denoising steps. The result is expressive but sample-inefficient.
Off-policy critic learning with a partial update to the generative process. They are performant with well initialized policies, but cannot improve weak policies that require balanced expressivity and sharpening via online interactions.
Freeze the GCP and learn a policy over the initial noise as actions to steer the generation process. Effective only where the base policy already covers good actions.
Cannot generate actions outside the support of the base GCP.
Freeze the GCP and learn a small additive correction to the final action. Well suited to a strong base policy needing only minor adjustments.
Can expand the support of the action distribution in a limited manner.
Train an off-policy critic, then finetune the GCP by SFT on Best-of-N actions ranked by the critic.
SFT cannot learn new behavior. It plateaus and is hyperparameter-sensitive.

OGPO builds on the bi-level view of GCP optimization introduced by Ren et al. (2024). Producing a single action requires running a denoising trajectory $a_{t,K} \to a_{t,K-1} \to \cdots \to a_{t,0}$, which unfolds an inner denoising MDP over generation steps, nested inside the outer environment MDP over executed actions.
The two levels differ sharply in cost. A step in the environment moves a physical robot and is therefore expensive; a step in the denoising process is a single forward pass, and is therefore cheap and trivially parallelizable. OGPO is organized entirely around exploiting this asymmetry.
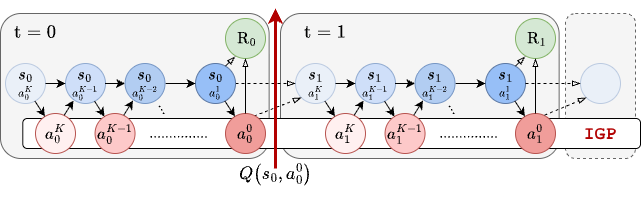
Learn the critic off-policy in the expensive environment MDP, so that every real transition is reused; then extract the policy with on-policy PPO entirely within the cheap denoising MDP, using the critic as a terminal reward. The result is the sample efficiency of temporal-difference learning together with the expressivity of full-policy updates.
Because the denoising trajectories are generated in the policy's own imagination, OGPO avoids the two pathologies of differentiating through a GCP: it never backpropagates through the denoising chain, and it never differentiates the critic, $\nabla_a Q$, which is unreliable in contact-rich tasks. The policy update is zeroth-order throughout.
OGPO treats each denoising trajectory as a short sequence to be optimized with PPO, in which the only reward is supplied at the end — the critic's value of the final action. For a state $s_t$ and a sampled trajectory $a_{t,K:0}$, the objective is the standard clipped surrogate, applied to the denoising trajectory alone:
Because no reward is dispensed at intermediate denoising steps, $\hat A$ is exactly the Monte-Carlo return of the trajectory. The ratio $\omega_\theta$ is an annealed importance ratio over the whole chain, so a single advantage conditions every generation step toward higher-value actions. The procedure rests on three components.
An ensemble of $M$ critics is trained off-policy with the standard temporal-difference loss over a long-horizon replay buffer. Targets use the mean over the ensemble; ablations show this is preferable to pessimistic min-aggregation in the sparse-reward setting.
By analogy to GRPO in language-model post-training, a buffer state $s_t$ plays the role of a prompt and each denoising trajectory the role of a response. We draw $N_{\mathrm{batch}}$ states and $N_{\mathrm{group}}$ trajectories per state, all in parallel and at no environment cost, and average the loss:
Parallel sampling yields a Monte-Carlo value baseline directly, $\hat V^{(i)} = \tfrac{1}{N_{\mathrm{group}}}\sum_j Q_{\mathrm{targ}}(s^{(i)}, a_0^{(i,j)})$, so OGPO requires no separate value network.
Flow ODEs have singular per-step likelihoods, leaving the PPO ratio ill-defined. OGPO injects Gaussian noise at each flow step to make the likelihoods non-singular, and applies a stochastic-interpolant correction so that the per-step marginals continue to match standard ODE sampling (this is important!).
execute a_t ~ πθ(·|s_t);
push (s_t, a_t, r_t, s_{t+1}, done) → buffer 𝓑
# critic update — off-policy, sample-efficient
update critics φ₁…φ_M with the TD error over batches from 𝓑
# actor update — on-policy PPO, in the GCP's imagination
for i = 1…N_batch:
sample state s⁽ⁱ⁾ ~ 𝓑; roll N_group denoising trajectories a⁽ⁱ,ʲ⁾ ~ πθ(·|s⁽ⁱ⁾)
baseline V̂⁽ⁱ⁾ ← mean_j Qφ(s⁽ⁱ⁾, a₀⁽ⁱ,ʲ⁾)
update actor with the aggregated PPO loss # no BPTT, no ∇ₐQ
EMA targets: θ̄ ← (1−τ)θ̄ + τθ; φ̄ ← (1−τ)φ̄ + τφ

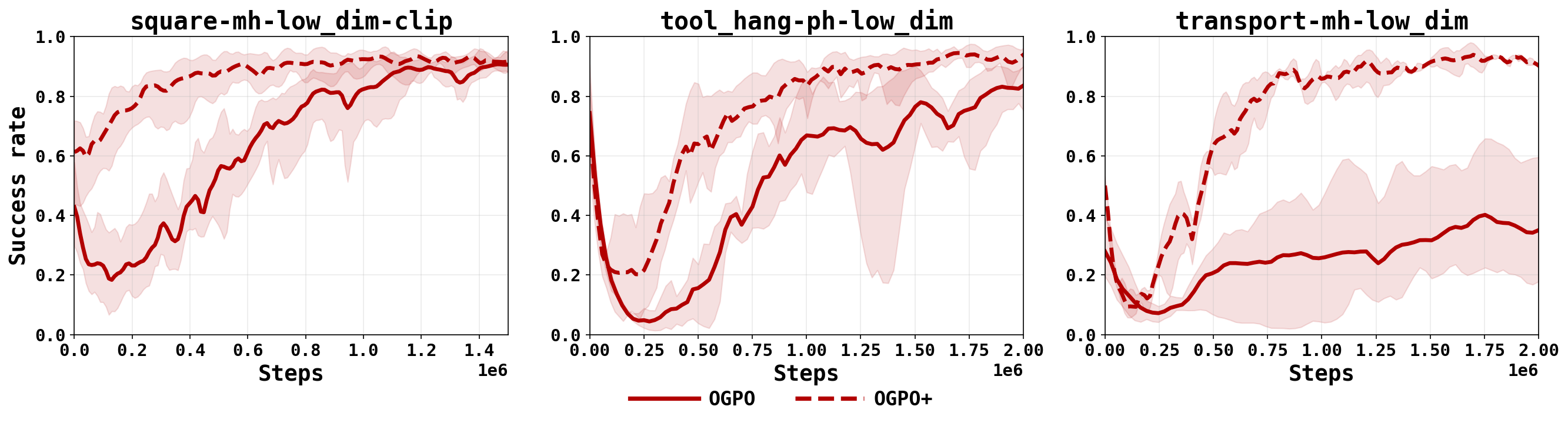
Aggressive policy extraction can overly exploit imperfectly learned critics. Moreover, under the sparse, −1-per-step reward typical in robotic manipulation, maximizing return trades completion rate against completion speed, and OGPO may learn to finish quickly at the expense of reliability. We propose two modifications, OGPO+ and OGPO+CA, that address these challenges, ensuring greater training stability and sample efficiency.
We maintain a success buffer $\mathcal{D}_{\mathrm{succ}} \subseteq \mathcal{D}_{\mathrm{roll}}$ of transitions from episodes that succeeded, and add a small cloning loss on it. The term is asymmetric: it raises the likelihood of empirically successful actions without lowering that of failures, so it places a floor under the modes that the PPO objective is allowed to abandon.
As noted above, full-policy finetuning is expressive enough to over-exploit an imperfect critic. This is most visible at the transition from offline pretraining to online RL. There, the critic ensemble has not yet reached agreement on actions outside the offline support, and that disagreement shows up as a performance dip at the offline-to-online RL transition."
Rather than altering the critic update, OGPO modifies the policy-extraction step to act only where the ensemble agrees. For each candidate action it uses a sign-consensus, or conservative, advantage:
The advantage is non-zero only when every ensemble member agrees on its sign, and then takes the most conservative magnitude consistent with that sign. Actions on which the ensemble disagrees contribute no gradient until on-policy data restores consensus, at which point the update recovers automatically.
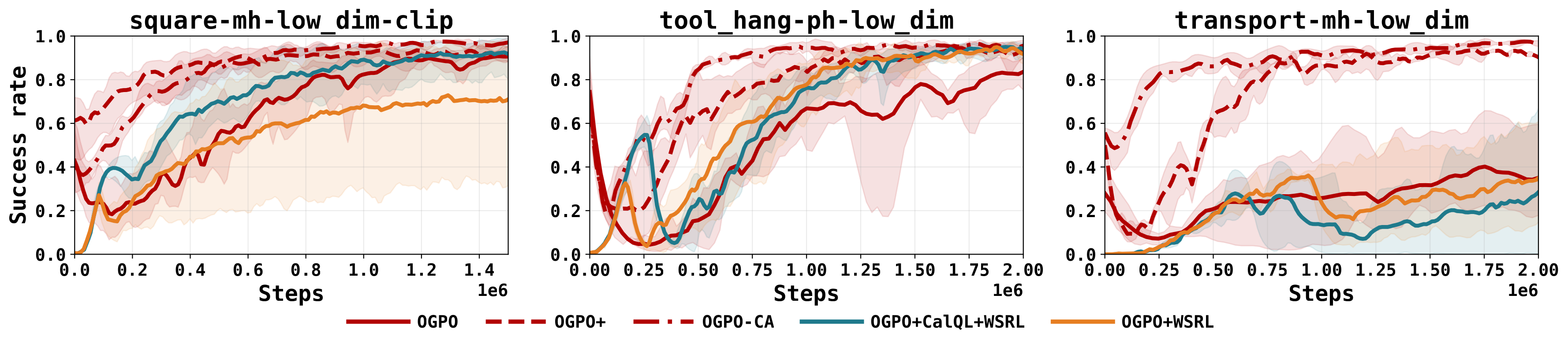
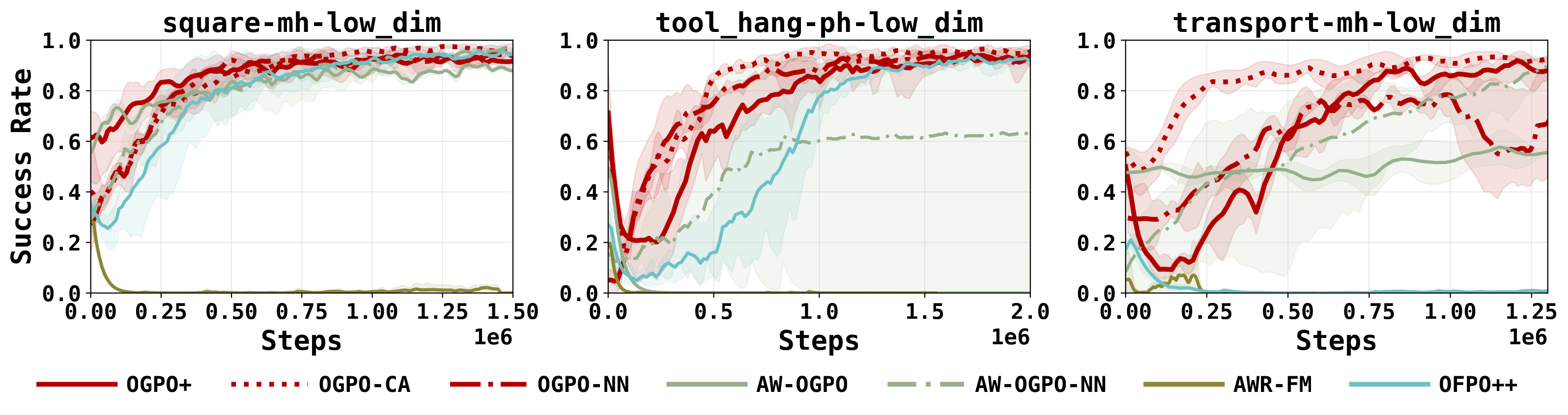
Every method begins from the same flow BC checkpoint, clipped to at most 50% success, and finetunes online with no offline or expert data in the replay buffer, a regime representative of real-world deployment. We evaluate across three families that span the hard parts of robot learning: , high-precision long horizon tasks (Robomimic), multi-task RL from partial and mixed datasets (Franka Kitchen), and short horizon dense reward dexterous manipulation (Adroit).
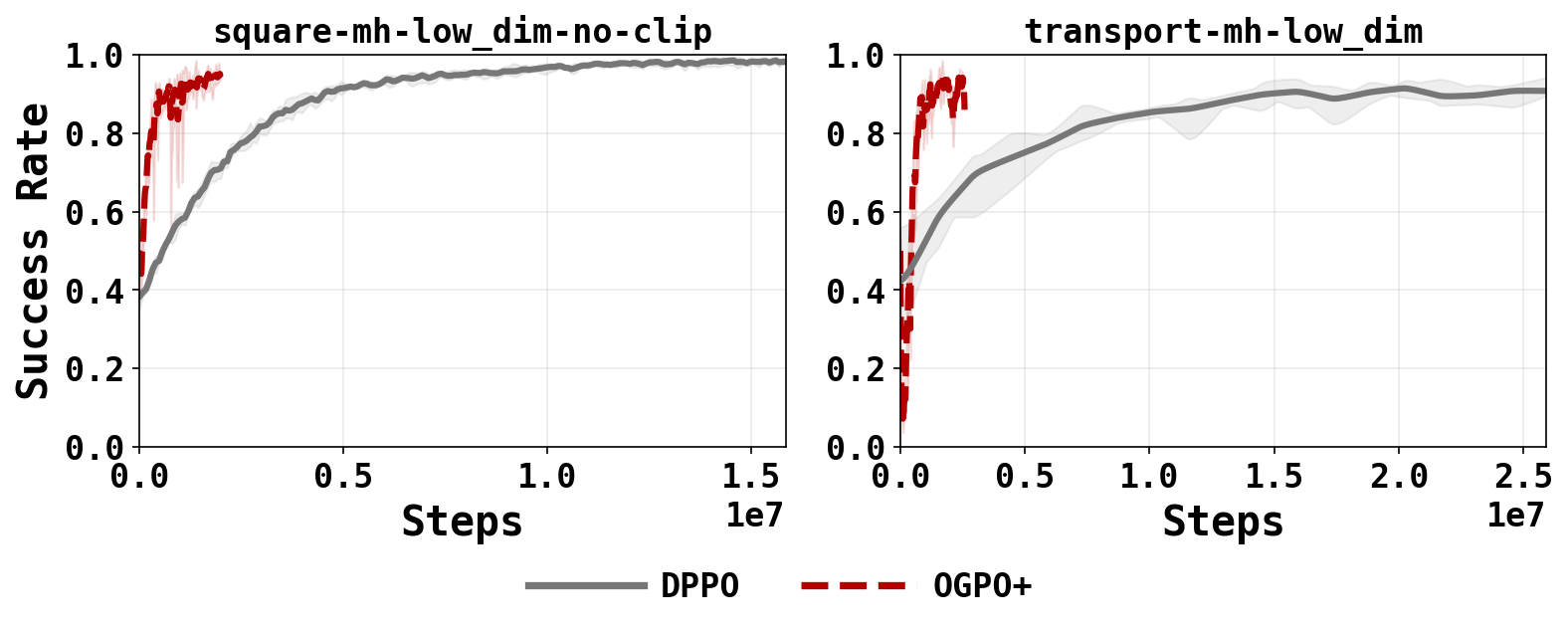
OGPO severs the bi-level MDP and uses an off-policy critic as a terminal reward, whereas DPPO applies on-policy PPO to the entire bi-level MDP. OGPO achieves an order of magnitiude higher success far sooner than DPPO, which is limited by the cost of environment interactions and the effective horizon of the denoising process.
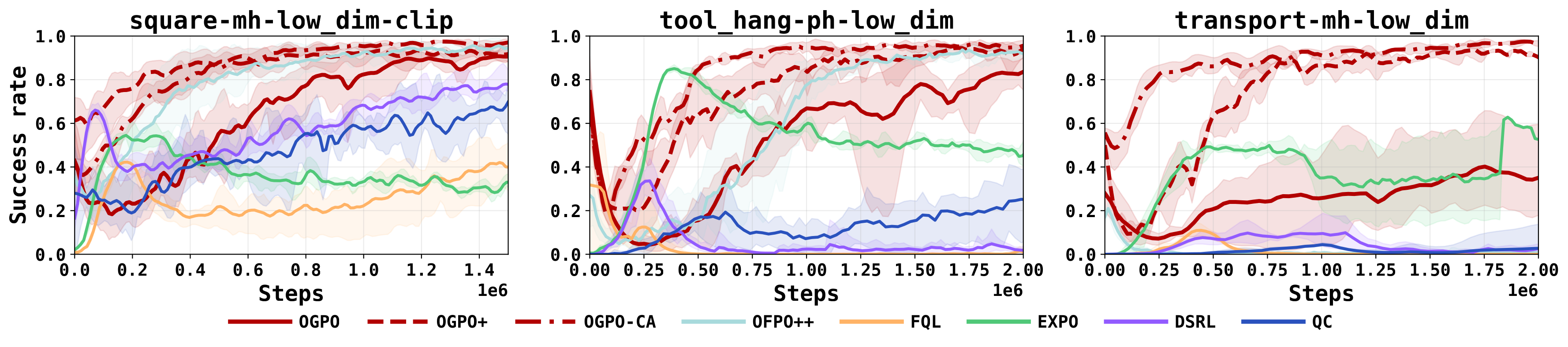
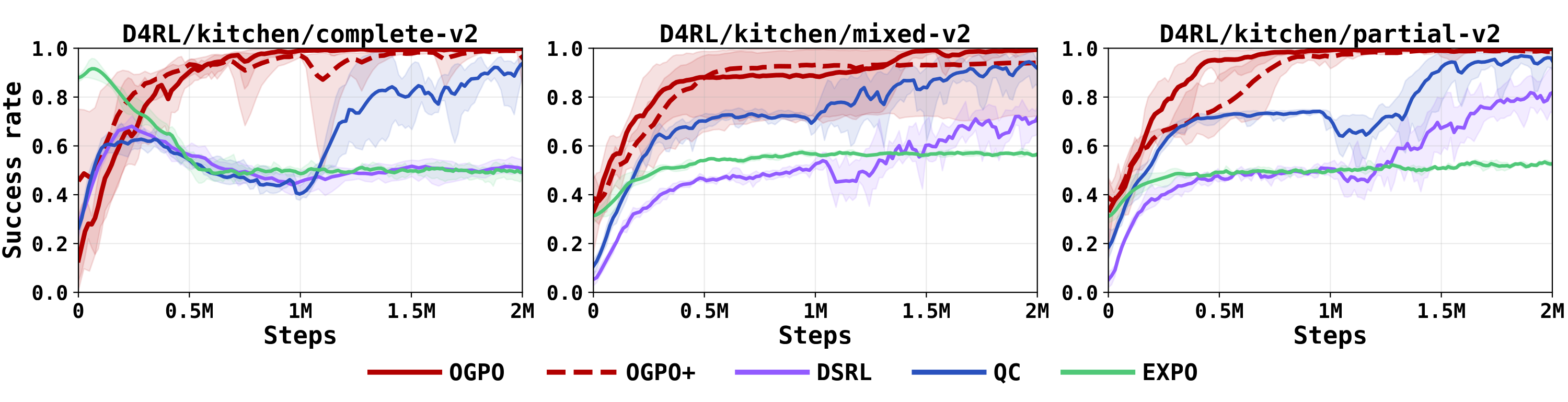

Read across the tasks, the pattern is consistent: each partial-finetuning method has a regime in which it fails, while OGPO is strong everywhere except dense, dexterous control, where residual learning is the more natural choice.
| Criterion | OGPO | QC | DSRL | EXPO |
|---|---|---|---|---|
| Mixed data quality | ✓✓ | ✓◔ | ◔◔ | ✗✗ |
| High-precision tasks | ✓✓ | ~◔ | ✗✗ | ◔◔ |
| Partial demonstrations | ✓✓ | ✓✓ | ~◔ | ✗✗ |
| Long horizon | ✓✓ | ◔✗ | ◔✗ | ✗✗ |
| Dense / dexterous | ~◔ | ~◔ | ◔✗ | ✓✓ |
| High sample efficiency | ✓✓ | ~✗ | ✗✗ | ◔✗ |
Rollouts from the clipped BC initialization. OGPO+ completes high-precision long horizon reliably, while the partial-finetuning baselines fail in characteristic ways.
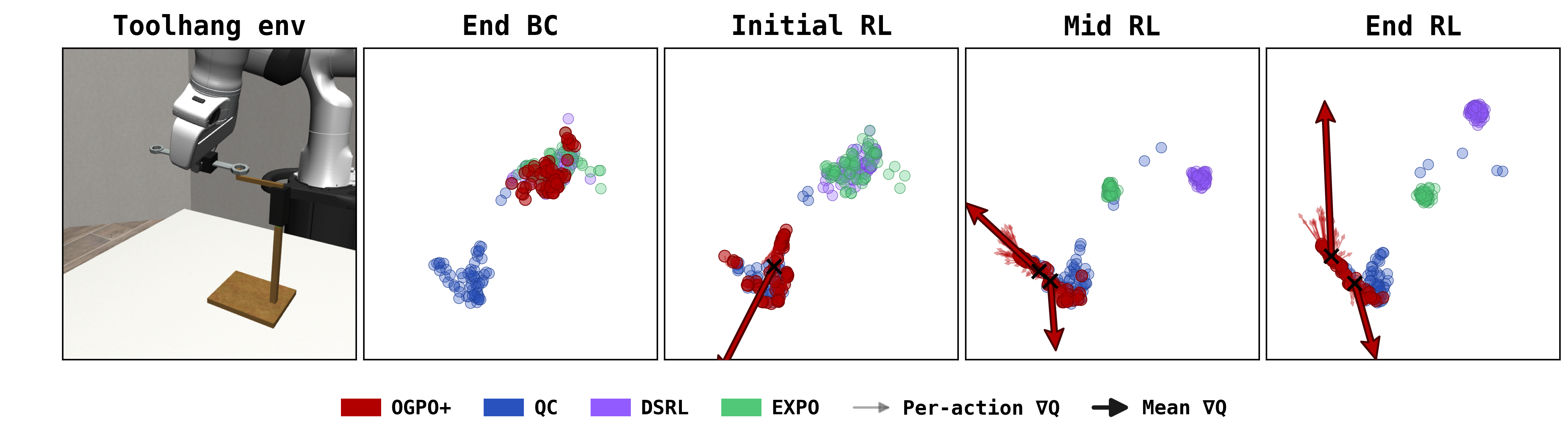
Here, we try to understand why OGPO outperforms other methods. Beyond the routine ablations, we uncover a surprising finding: OGPO drives exploration, rather than merely sharpening the base policy.
Whereas diversity, optimality and task efficiency are often regarded as being at odds, we show that OGPO accomplishes all simultaneously. Below, we present extensive evidence for this finding, and propose a mental model, summarized in the figure caption below as to how OGPO achieves this affect.
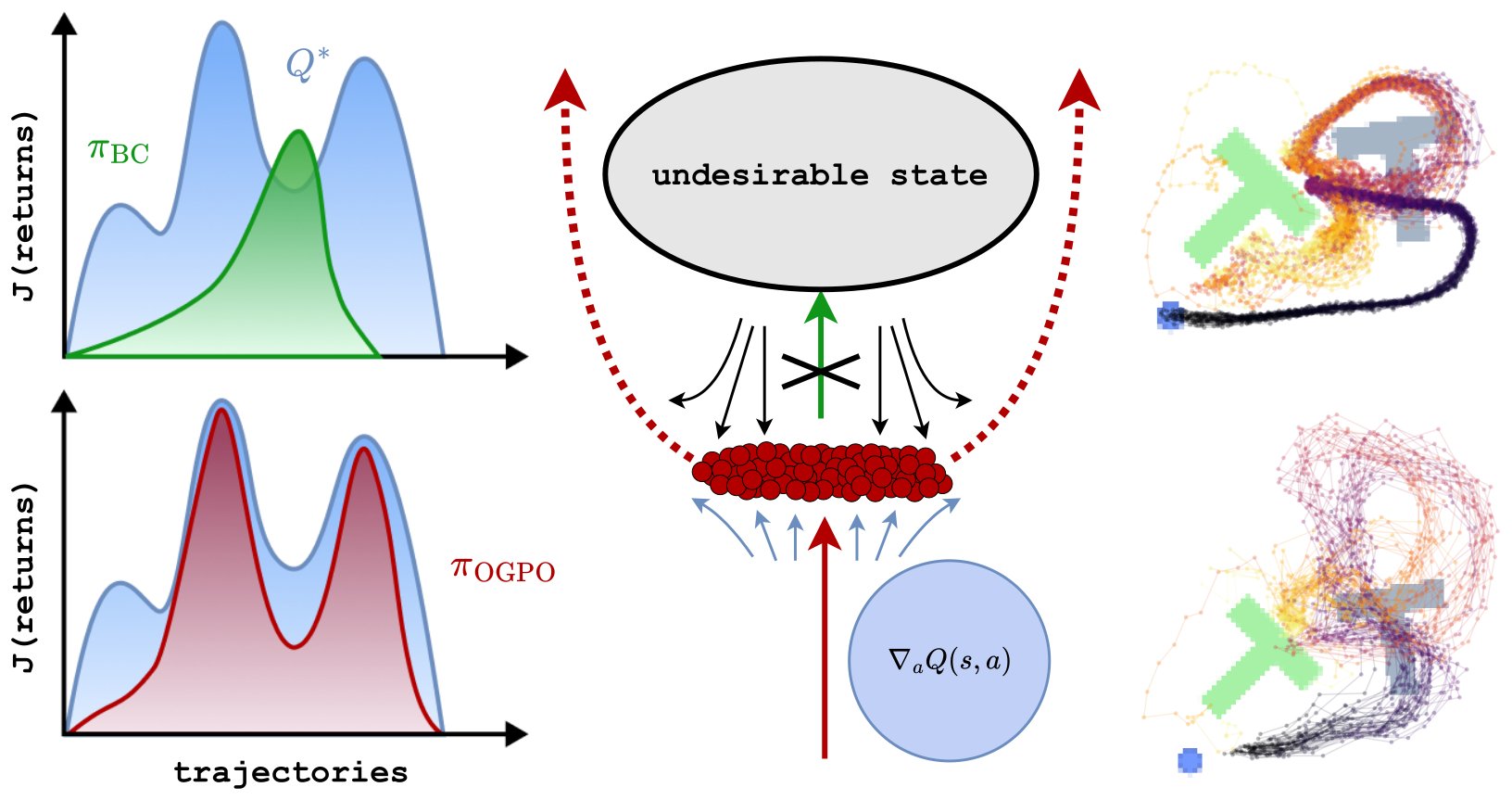
OGPO does not increase variation isotropically: rather, the remaining action-variance as even orthogonal to the critic gradient. Note that, along these directions, differences in actions have zero effect on critic values, to first order. Therefore, we find the OGPO allocates large variance along directions which do not affect task success. At the same time, OGPO (a) sharpens the distribution orthogonal to these directions (resulting in the “thin” ellipsoid seen in Mid/End training), while (b) aggressively “stretching” the action distribution to align with critic gradients in parts of the action distribution when gradients ∇aQ(s, a) exhibit strong consensus, e.g. ψ > 0.6. Thus, OGPO can both optimize the critic for task performance/completion time while simultaneously preserving as much action diversity as possible.
OGPO is modular: with the off-policy critic fixed, the extraction objective can be replaced. Comparing PPO against advantage-weighted regression (AWR, with its asymmetric and positive-only variants) and Flow Policy Optimization (FPO), PPO-style extraction is the most performant across tasks.
OGPO shines on sparse reward tasks in low-data regimes. However, it has the following limitations:
@article{patil2026ogpo,
title = {{OGPO}: Sample Efficient Full-Finetuning of Generative Control Policies},
author = {Patil, Sarvesh and Nakamoto, Mitsuhiko and Agarwal, Manan and
Saxena, Shashwat and Zhang, Jesse and Anantharaman, Giri and
Winston, Cleah and Pan, Chaoyi and Chen, Douglas and Huang, Nai-Chieh and
Temel, Zeynep and Kroemer, Oliver and Levine, Sergey and Gupta, Abhishek and
Dai, Hongkai and Shah, Paarth and Simchowitz, Max},
journal = {arXiv preprint arXiv:2605.03065},
year = {2026}
}
OGPO = Off-Policy Generative Policy Optimization.