
Introduction
Behavior Cloning (BC), or learning from human demonstration, is a foundational component of modern robotic learning. Though BC has been studied for decades in other domains (Pomerleau, 1988), only recently has it been seriously applied to robotic manipulation tasks. Though these successess have been attributed to the use of generative models (e.g. diffusion models) as parametrizations for control policies, a second ingredient of equal importance is the practice of action-chunking (AC), where policies predict and execute open-loop sequences of actions, or “chunks” (Chi et al., 2023; Zhao et al., 2023).
In this writeup, we aim to answer:
1. Why does action-chunking help behavior cloning in robotic manipulation?
2. When action-chunking doesn’t work, what else can be done?

Action-chunking policies predict entire sequences of future control actions and executes them without querying the policy again. These actions are generally used as inputs to a lower-level position-based controller.
Our findings crucially depend on the properties of both the open-loop dynamics (where actions are generated without access to the underlying state) and the closed-loop dynamics (where actions are based on the current state and we must consider the combined environment + policy system as a whole).
Summary of Findings
There are a number of speculated benefits associated with action-chunking, including improved representation learning, multi-modal prediction, and receding-horizon control. However, we identify a more fundamental benefit: action-chunking encourages stability of the learned policy in closed-loop interaction with the environment, mitigating compounding errors.
When the underlying environment is inherently stablizing (i.e. open-loop stable), action-chunking alone suffices to prevent compounding errors, leading to horizon-free imitation guarantees. In contrast, without action-chunking, prior work (Simchowitz et al., 2025) show that errors can grow expoenntially in the problem horizon, even when the dynamics are stable.
We validate this finding in simulated robotic manipulation tasks from RoboMimic, where we observe that increasing chunk-lengths leads to significant improvements in task success rates. We do so even for deterministic policies imitating a deterministic expert, confirming that the benefits of action-chunking can be realized even in the absence of multi-modality or partial observability.


RoboMimic tool-hang task success, as a function of both prediction horizon and evaluated chunk length. Center: Chunk length ablation, 100 training trajectories. Right: Ablation on noise injection vs no noise injection, 50 training trajectories.
Informally, stability of a dynamical system measures its sensitivity to compounding errors: stable systems attenuate small perturbations over time, while unstable systems amplify them.. As described below, open-loop stability is a valid assumption for many robotic manipulation settings, where the robot interacts with objects in a quasi-static manner via end effector control.
However, when the underlying environment is not open-loop stable, action-chunking alone is insufficient to prevent compounding errors, and can even make compounding error worse. In fact, Simchowitz et al. ‘25 show that, in this regime, no algorithmic modification suffices to mitigate error compounding. Instead, we need better data. To this end, we consider a simple practice where the expert demonstrator adds a small amount of well-conditioned noise to their actions during data collection, but collects ground-truth action labels.
We show that a simple exploratory data collection procedure suffices to prevent compounding errors, even when the underlying environment is not inherently stabilizing, provided that the expert demonstrator is capable of correcting from errors.
The effect of noise injection during demonstration collection for unstable environments can be easily understood by examining reward accumulation over a single trajectory in a continuous control environment such as the MuJoCo continuous control suite:
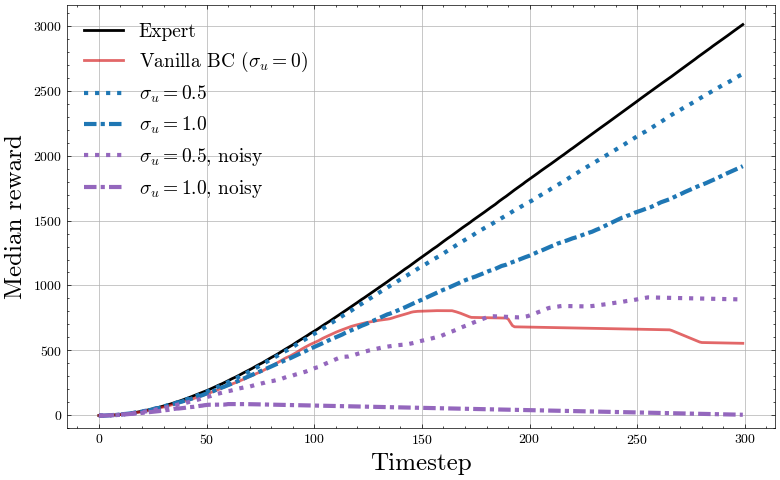
Mean accumulated reward for Half-Cheetah environment by timestep, with differing levels of noise injection and using the clean expert actions vs noised expert actions for the training labels.
For the adventurous reader, we will now introduce the general framework we use to make precise these fuzzy notions of stability and performance. This requires elements from Control Theory with which many Roboticists and RL theoristists may be unfamiliar with. We build up our analytical framework in a notation-light and broadly informal manner.
Preliminaries
To isolate the effects of compounding error, we consider the minimal setting a fully observed, continuous state-action environment. Speficially, we adopt the language of a control system as a natural abstraction for decision making in robot learning.
A determinsitic1, discrete-time, continuous state-action control system is defined by
- States
- Control inputs
, which correspond to actions. - Dynamics deterministically evolving according to
.
Thus, a control system is just an Markov Decision Process (MDP) with deterministic transitions and no rewards, tailored to continuous state and action spaces. We assume the initial state is drawn
Imitation Learning in Control Systems
Our goal is to learn a policy
A deterministic policy
We say
Throughout the rest of this post we will assume that we have been given access to some number of demonstration trajectories sampled from
The Compounding Error Problem
One of the key challenges in Imitation Learning is that of Compounding Error (Simchowitz et al., 2025), which we can now formalize explicitly,
An imitation learning algorithm
In other words, imitating via empirical risk minimization on a given demonstration distribution
As proposed in prior work (Pfrommer et al., 2022; Tu et al., 2022), compounding error can be understood through the lens of control-theoretic stability, which describes the sensitivity of the dynamics to perturbations of the state or input. We specifically consider the following notion of incremental stability, which models the rate at which two trajectories converge or diverge under different control inputs.
A system
We say a policy-dynamics pair
Intuitively,

EISS captures the ability of a system to naturally correct errors.
Is EISS of the open-loop dynamics
We believe so. Many robotic manipulation settings involve quasi-static interactions between the robot and objects, where the learned policy controls the position of the end-effector directly, and the objects move in response to contact forces. In these settings, the dynamics from end-effector commands to object states are often stable, as small perturbations in end-effector position lead to small perturbations in object position, without amplification over time.
This means that for most settings, the components of the state corresponding to the environment are at worst marginally stable (

Open-loop EISS abstracts the presence of a stabilizing lower-level control algorithm, such as a PID-based position controller.
Given an EISS system (for either
However, this is unfortunately not the case. This surprising fact is formalized in our prior work (Simchowitz et al., 2025), which we restate (informally) here:
There exist families
-
For every
, the open-loop and closed-loop are both EISS and are Lipschitz and smooth. However any algorithm which returns smooth, Lipschitz, Markovian policies with state-independent stochasticisty must suffer exponential-in- compounding error for some . -
For every
, is not necessarily EISS, but the closed-loop is EISS and are Lipschitz and smooth. However any algorithm , without restriction, must suffer exponential-in- compounding error for some .
Indeed, it is possible to construct fairly simple (dynamics, expert) pairs
This naturally sets the stage for our twin results:
-
For any EISS-stable
, using action chunking provably avoids compounding error. This bypasses the first hardness lower bound as chunking policies maintain internal state (the chunk sequence) and are therefore non-Markovian. By choosing action-chunk lengths that are sufficiently long, we can guarantee that the closed-loop under the learned policy is always EISS. -
For any EISS-stable
, where may potentially be unstable, a simple modification to the data collection procedure using noise-injection (à la DART, Laskey et al. (2017)) is sufficient to guarantee that under the learned policy is EISS. The hardness results rely on
(and therefore, ) which explore only a subspace of the actual reachable portions of the subspace. This allows all to share the same distribution and makes the “true” choice of opaque to the learning algorithm. By modifying the data collection procedure from , we can make uniquely identifiable from and bypass the lower bound.
Note
Footnotes
Action-Chunking Does Prevent Exponential Compounding Errors in Open-Loop Stable Systems
Action-chunking is a popular practice in modern sequential modeling pipelines, where a policy predicts a sequence of actions, of which some number are played in open-loop. There are various intuitions of the practical benefits of action-chunking, ranging from:
- Robustness to non-Markovian / partial observability quirks in the data.
- Amenability to multi-modal prediction.
- Improved representation learning via multi-step prediction.
- Simulating Model-Predictive Control.
We show a different mechanism, one not described by the past literature: action-chunking can leverage the open-loop stability of the system to stabilize the learned policy.
A chunking policy is specified by a chunk-length
For convenience we also write
We now formalize action-chunking for imitating deterministic expert policies:
We sample
Our novel motivation behind this cmmon intervention is that, by making the chunk length long enough, the learned policy

Let the true dynamics
Then we have the trajectory-error bound for any
This implies that when the ambient dynamics
Our result follows from the following fact: under natural assumptions, the learners chunked policies are all closed-loop EISS. This circumvents the lower bound given earlier, in which it is hard for the learner to find policies which stabilize the dynamics if those policies must predict a single action at a time.
Noise Injection Mitigates Compounding Error under Smooth, Unstable Dynamics
We now consider the difficult setting where the ambient dynamics
We define the expert distribution under noise injection as the distribution
Our key innovation over prior algorithms such as DAgger or DART is that we learn using a weighted mixture of both the noise-injected
Using a mixture is provably better, particularly in the high data regime with large
For the noise-injected distribution

We can think of the data mixture as ensuring coverage both on-expert, as well as a “tube” around the expert trajectories. Using either one or the other is suboptimal, either due to lack of on-expert data, or off-expert data.
Our results in this domain make extensive use of the analysis tools introduced in Pfrommer et al. (2022), which provides strong guarantees when imitating a closed-loop EISS expert in an adversarial manner.
There are many technical subtleties that we gloss over here but explore in-detail in our full manuscript. Namely our analysis is carefully constructed to consider coverage only on the manifold of reachable states. To perform this analysis in a technically rigorous requires careful Control-Theoretic analysis involving concepts such as the Controllability Grammian. We additionally make several simplifying assumptions regarding first-order-smoothness (i.e that
Let the dynamics and expert policy
we have:
In particular, setting
Experimental Validation
Action Chunking
To validate our predictions about the stability-theoretic benefits of action-chunking, we propose experiments on robotic imitation tasks in the RoboMimic framework. We find that:
- Executing action chunks matters more than simply predicting longer sequences of actions. This demonstrates the action-chunking is more than a simple consequence of representation learning, or a simulation of receding-horizon control.
- The merits of action-chunking remain showcased in deterministic, state-based control. This reveals that action-chunking still improves performance independently of partial observability or compatibility with generative control policies.
- End-effector control enables the benefits of action-chunking. This is because end-effector control renders the closed-loop between system state and end-effector prediction incrementally stable. Hence, the low-level end-effector controller transforms imitating the position policy to taking place in an open-loop stable dynamical system, precisely the regime where we prescribe our AC guarantees.
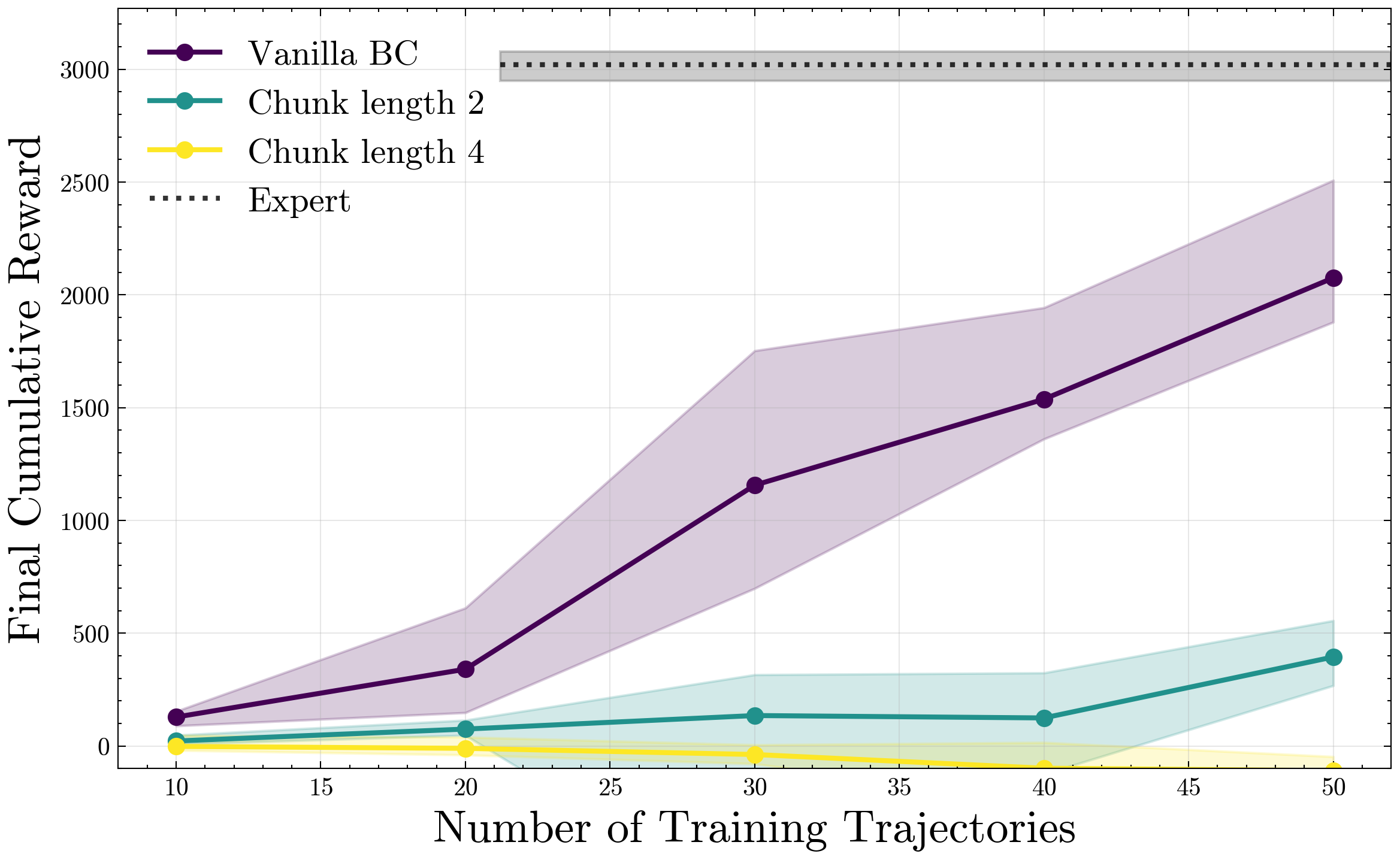
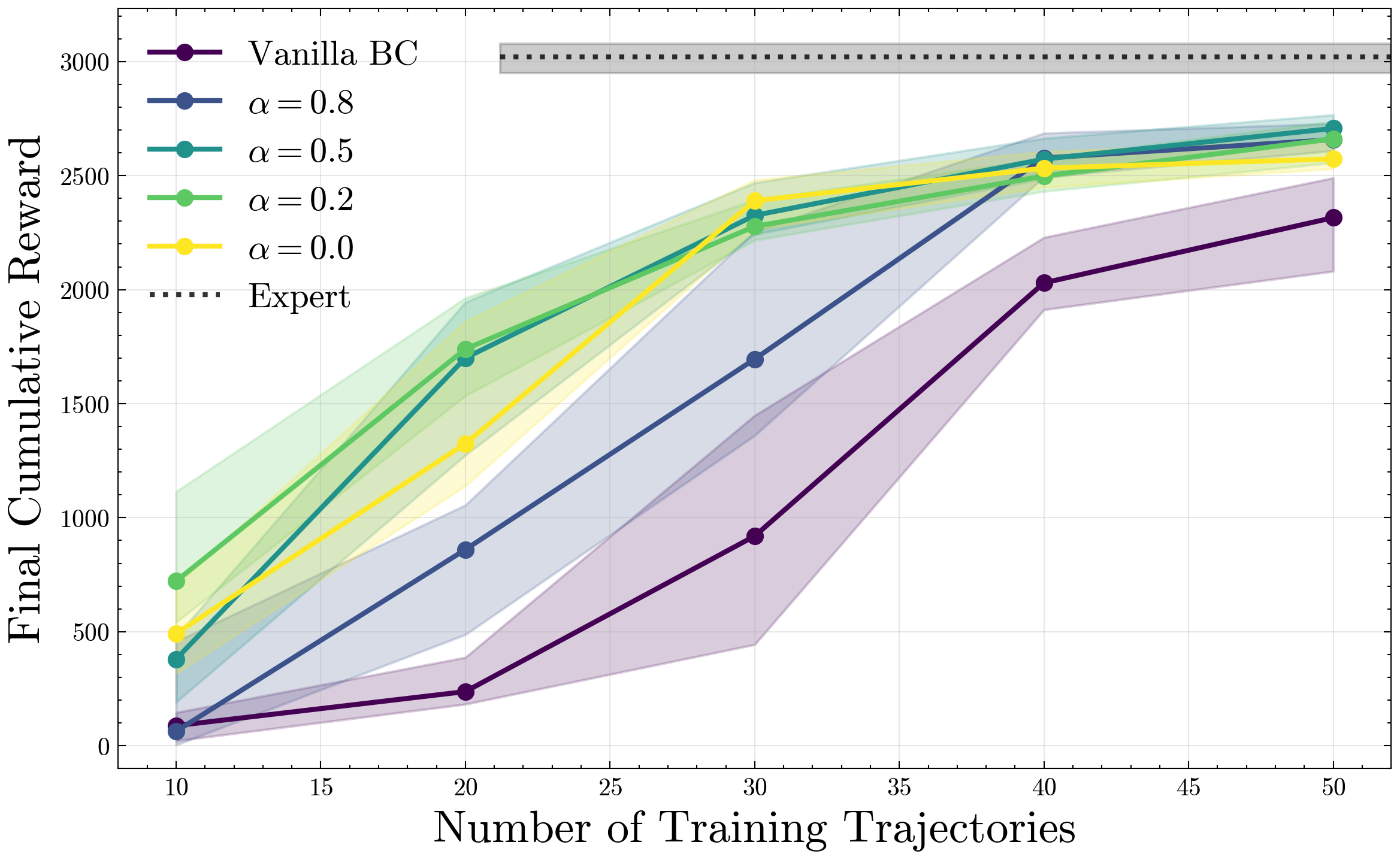
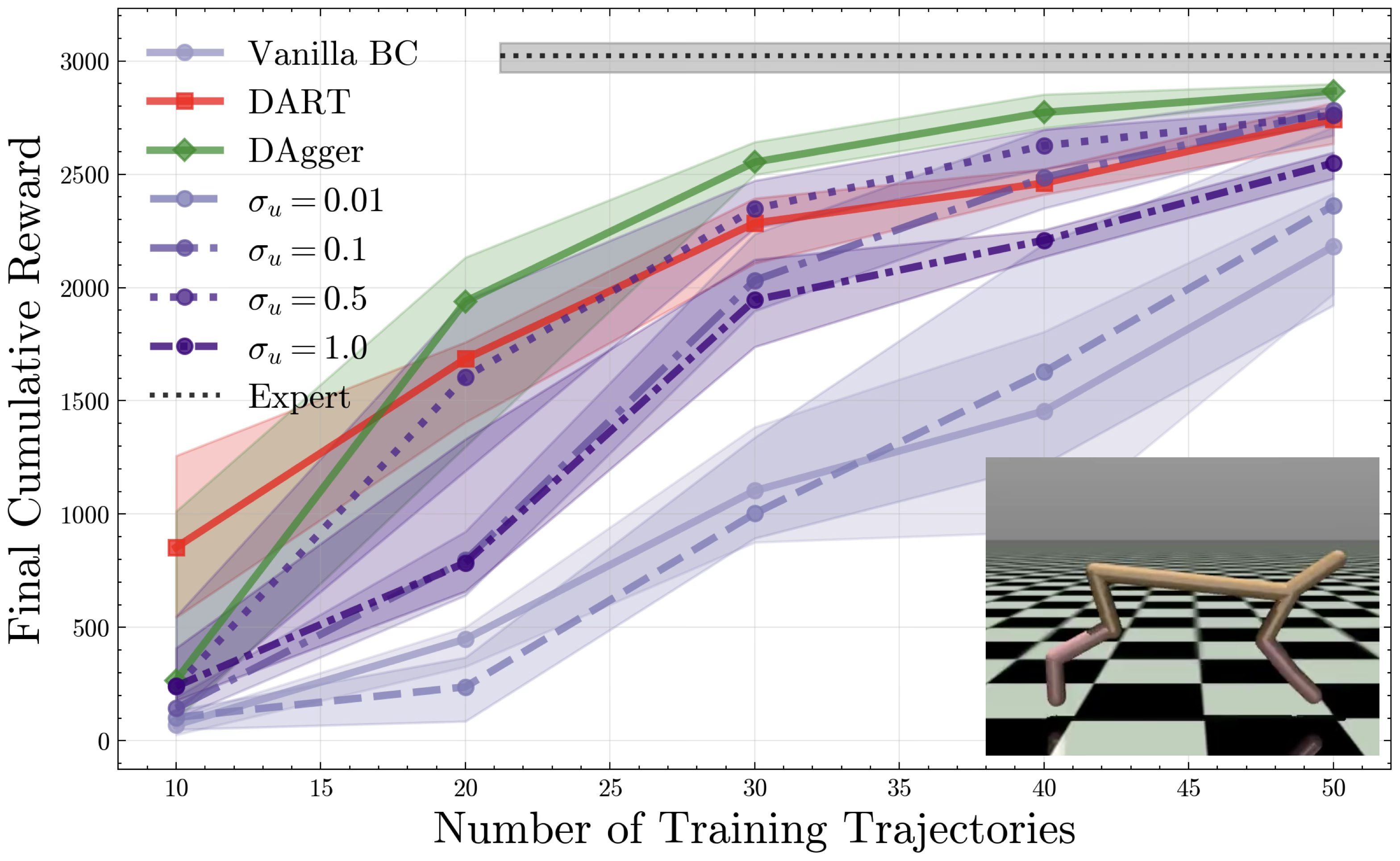
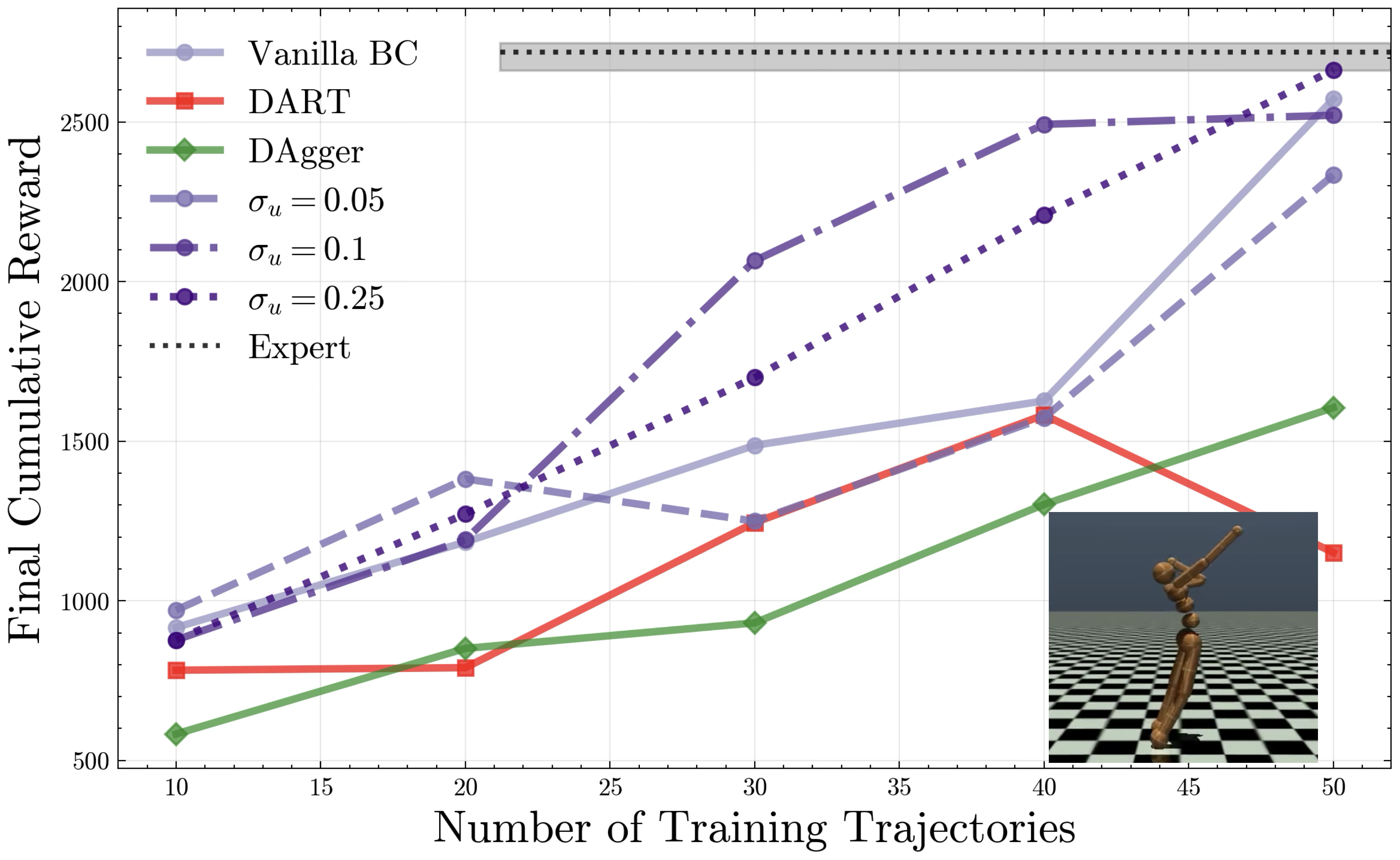
We visualize performance as a function of noise injection and chunk length for the MuJoCo HalfCheetah environment, and show performance relative to both DAgger and DART on HalfCheetah, Humanoid.
Noise Injection
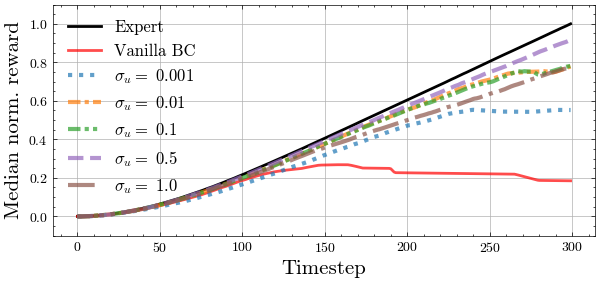
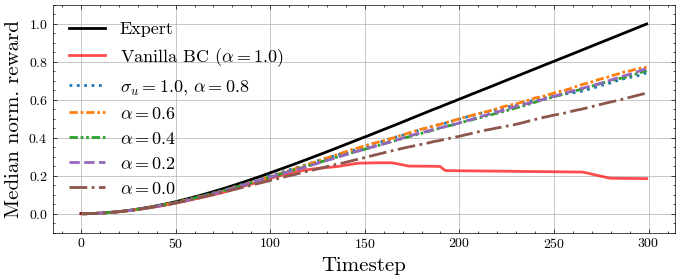
We seek to validate our hypotheses about the exploratory benefits of noise-injection. We propose experiments on MuJoCo continuous control environments, where we seek to imitate pre-trained expert policies. To summarize:
- Noise injection as in Intervention 2 provides the exploration necessary to mitigate compounding errors, increasing performance on par with iteratively interactive methods such as DAgger and DART. We note Intervention 2 collects data in one shot, without ever observing learned policy rollouts.
- Larger noise scales
(within tolerance) improve performance, in contrast to prior understanding which necessitates set proportional to , i.e. very small for policies with low on-expert error. - A mixture of noise-injected and clean expert trajectories is beneficial, and the difference is small when provided more data. This matches the theoretical intuition that noise-injection is necessary up until
is “locally stabilized” sufficiently well around , and thus only enters the trajectory error as a higher-order term.
Discussion and Limitations
Our combined action-chunking, noise-injection procedure relies on a structural assumption of either
Without either of these assumptions, if
For settings where an external oracle can stabilize the dynamics (e.g. a low-level position-based control loop), the dynamics can be reformulated such that